AIで骨格検出、人の姿勢解析や行動分析に活用
製造産業、スポーツ、医療・リハビリ、小売、エンタメ分野の大手・中小企業も実績多数。
エイベックス、トヨタ自動車他、シリーズ販売累計500社突破!
導入実績



初めてのお客様へ
About VisionPose
VisionPoseは、カメラ映像から人の骨格情報をリアルタイムに検出する、高精度な姿勢推定AIエンジンのSDK(ソフトウェア開発キット)です。
解析から得た骨格データは、用途やジャンルを問わず商用利用や研究・開発に利用できます。
- 人体30キーポイントを最大60FPSでリアルタイムに検出可能※PCスペックで変動
- 2台のカメラで3D推論(Standard)と、1台のカメラで3D推論(Single3D)に対応
-
すぐに使える2つのアプリ
を標準添付
1) リアルタイムの姿勢推定と映像への表示(BodyAndColor)※ソースコードつき2) 動画や静止画の電子ファイルを使った姿勢推定(VP Analyzer)※Single3D iOS版を除く - 商用利用を含め、用途に制限はありません
- SDKとして提供しており、C#/C++/Swiftでの開発が可能
- 追加学習 が可能 ※追加学習はオプションサービスで、実施には条件があります
特長・機能

製品ラインナップ
VisionPose(スタンダード)
精度重視の標準SDK。2D/3D解析で全身30ポイントの骨格検出と最大60FPS(※PCスペックで変動)を実現。
-

- ・Windows C#,C++
・Linux - ネットワーク(IP)カメラに対応 。クラウドベースでのご利用も可能です。
-


- ・Jetson AGX Xavier
・Jetson Xavier NX - 精度そのままに、 NVIDIAの小型エッジデバイスに対応 。省スペースの組み込みが必要なIoT開発などに。
カメラ1台/2D解析/30ポイント
カメラ2台/3D解析/30ポイント
※ファイル解析はカメラ不要
VisionPose Single3D
単眼の3D解析機能を搭載したSDK。キャリブレーション不要で手軽にモーションキャプチャ。
-

- ・iOS/iPadOS、Android
- iPhone/iPad、Androidアプリ開発向けSDK。モーションキャプチャを利用したアプリ開発などに。
-

- ・Windows Unity
- UnityでのCGキャラクターのアニメーション作成やゲーム開発などに。
カメラ1台/2D解析/30ポイント
カメラ1台/3D解析/17ポイント
※ファイル解析はカメラ不要、iOS/iPadOSとAndroidはファイル解析不可
※iOS/iPadOSとAndroidのカメラ制御には別途アプリ開発が必要です。
VisionPose Nano
手軽で低コストなAI姿勢推定エンジン。ボーンの長さと関節角度の測定アプリが新たに追加。
-


- ・NVIDIA Jetson Linux
- ハードウェア付属の研究用として提供。安価で手早く骨格検出を行いたい場合に最適です。
カメラ1台/2D解析/30ポイント
(軽量版=カメラ1台/2D解析/22ポイント)
※商用利用できません。
※3D解析不可
※ファイル解析はカメラ不要

解析された骨格情報は、様々な分野で利用可能
独自のAIエンジンで、環境を選ばない骨格検出が可能

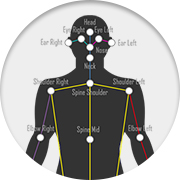




製造産業、スポーツ、医療・リハビリ、小売、エンタメ分野の大手・中小企業も実績多数!
シリーズ販売累計500社突破!
VPシリーズ累計販売1373本 2026年6月30日時点集計
- 業種別お問い合わせ
- 用途別お問い合わせ
【導入事例】お客様の声

バラエティー番組「JO1CX-TV」にてダンス・シンクロ度判定AI「VP Synchro Checker」を提供

コナミアミューズメントの最新ダンスゲーム「DANCE aROUND」にVisionPoseを提供

顔認証パッケージソフトウェア Bio-IDiom KAOATO に使用

ダンススキル評価アプリ「エイベックス・ストリートダンス検定」に提供

リハビリテーション支援ロボット「ウェルウォークWW-2000」にVisionPoseを提供
お見積もり・開発のご相談など
ご購入・お見積もり、開発のご相談やご不明な点がありましたら、気軽にお問い合わせください。
教育機関や学校法人様向けのアカデミックライセンスご希望も承っております。
※現在、法人のお客様のみの販売・ご提供となります。ご了承ください。
導入手順
ご注文からセットアップまでの
全体の流れをご説明いたします。
FAQ
お客様から寄せられた
よくあるご質問をまとめています。
資料ダウンロード
本製品のカタログPDFを
ダウンロードできます。
VisionPoseに関連するブログコンテンツ

姿勢推定AI技術で検出した関節の位置から角度を計算するには?計算式から詳しく解説
姿勢推定AIエンジン「VisionPose」シリーズの1つ「VisionPose Nano」で、骨格の位置はわかったけど、関節の角度の計算方法がわからない方向けにコピペするだけで角度が出せるエクセルシートをご用意しました。

【モーションキャプチャ】姿勢推定技術の活用シーンを具体的な事例を元に業種別で紹介!アイディア出しに【行動認識・骨格検出】
人物の関節をはじめとした特徴点を座標データで検出する技術を使用することで、産業分野やスポーツ業界、医療・リハビリ・ヘルスケア、エンターテイメントなど様々なジャンルに活用できます。弊社へ実際にいただいたお問い合わせや開発事例を元に、具体的な姿勢推定の活用例をご紹介します。
【2021年最新】ホネホネ技術って?WEBカメラだけで全身モーキャプできる姿勢推定AIエンジン『VisionPose』とは?【PoseEstimation】
ネクストシステムは、AIやxR(VR、AR、MR)の最先端技術を活用したソフトウェア開発会社です。AIの中でも特に画像認識を得意としており、その技術を応用して独自に開発したAI姿勢解析エンジン「VisionPose」は人間の骨格情報を検出できます。「VisionPose」について詳しくご紹介します。

手のひらサイズのPCでAI骨格検出!?安価で操作簡単なプラットフォームVisionPose Nanoとは?
AIで人間の骨格を検出できるAI骨格検出エンジン「VisionPose」は、250社を超える企業に導入いただいています。様々なシリーズがある中の1つである『VisionPose Nano』がどういった製品なのか、普通のVisionPoseと何が違うのか。その違いについてご紹介します。

【機能・動作比較】新たなモーキャプ技術、ARKit3ってどうなの?ミチコンPlus(VisionPose Single3D)と比べた話
Apple社が提供するiPhone・iPad向けのAR対応アプリ「ARKit3」がリリースされました。弊社では独自開発のAIエンジンを使ってスマホやタブレットだけでモーションキャプチャを実現している『ミチコンPlus』をリリースしています。『ARKit3』と弊社モーキャプアプリ『ミチコンPlus』での比較検証をまとめてみました。

VisionPose®が追加学習で精度調整が可能に!教師データを作成するアノテーションツールとは?
AIとWEBカメラを使って人間の骨格を検出するシステム『VisionPose』では、学習済データ(モデル)の追加学習が可能になり、さらに特定動作の教師データを作成するシステム『アノテーションツール』を開発しました。これにより自社での追加学習が可能になったので、VisionPose®の追加学習周りをご紹介します。
-
 News2025.08.18
News2025.08.18
【累計販売1,000本/導入企業500社】VisionPose アップデート情報のお知らせ -
 News2025.07.04
News2025.07.04
姿勢推定AIエンジン「VisionPose」シリーズ導入企業が500社を突破しました! -
News2025.05.14
【累計販売1200本/導入企業450社】VisionPoseアップデート情報のお知らせ -
 News2025.05.03
News2025.05.03
【NHK総合】5月10日(土)放送の「所さん!事件ですよ」にて、弊社の骨格検知のVTRが紹介されます! -
 News2025.02.03
News2025.02.03
2025年1月リリース情報まとめ -
 News2025.01.20
News2025.01.20
【セール情報】VisionPoseシリーズ1000本達成記念!1月20日より10%OFFの決算セールをはじめます! -
 News2025.01.06
News2025.01.06
2024年12月リリース情報 -
 News2024.12.02
News2024.12.02
姿勢推定AIエンジン「VisionPose®」を使った、暗視カメラの映像解析デモ動画を公開しました。 -
 News2024.12.02
News2024.12.02
2024年11月リリース情報 -
 News2024.11.29
News2024.11.29
AI行動解析システム「VP-Motion」で粘着クリーナー作業解析の事例動画を公開しました。 -
 News2024.11.28
News2024.11.28
VR作業負荷解析システム「VR-Ergono」のページを公開しました。 -
 News2024.11.19
News2024.11.19
エリアへの不法侵入をAIで自動検知!「VPエリア内異常検知アプリケーション」の活用事例動画を公開しました。 -
 News2024.11.18
News2024.11.18
【セール情報】VisionPoseシリーズ販売累計1000本達成!! 11月20日よりネクストシステムのAI製品10%OFFの感謝セールを実施します -
 News2024.11.11
News2024.11.11
AI行動解析システム「VP-Motion®」がバージョン1.3.1にアップデートしました。 -
 News2024.11.06
News2024.11.06
AIエルゴノ評価システム「VP-Ergono」でトレーニングやスポーツシーンの活用事例動画を公開しました。 -
 News2024.10.29
News2024.10.29
作業現場の不安全行動検知に!ポケテナシ特集ページを公開しました! -
 News2024.10.15
News2024.10.15
AI行動解析システム「VP-Motion」が、3つの新機能を追加して大型アップデートしました! -
 News2024.09.12
News2024.09.12
姿勢推定AIエンジン「VisionPose」が米国の商標登録を取得しました -
 News2024.09.02
News2024.09.02
2024年8月リリース情報 -
 News2024.08.05
News2024.08.05
姿勢推定AIエンジン「VisionPose®」シリーズ販売ライセンス数950本を突破!
VisionPose (スタンダード)
-
ver.1.9.0
Windows C#Windows C++Linux2025.05.14CUDA/TensorRTのバージョンを更新。cuDNNの依存除去。
-
ver.1.8.1
Windows C#2023.11.06マニュアル修正。不具合修正。
Windows C++2023.11.06マニュアル修正。
-
ver.1.8.0
Windows C++Linux2023.09.15 USBドングルによるアクティベーション に対応。不具合修正。
Windows C#2023.08.01 USBドングルによるアクティベーション に対応。不具合修正。
-
ver.1.7.0
Windows C#,C++2023.02.28CUDA/cuDNN/TensorRTのバージョンを更新
Linux2023.03.13CUDA/cuDNN/TensorRTのバージョンを更新
対象OSをUbutnu 20.04に変更 -
ver.1.6.5
Windows C#,C++Linux2022.10.03不具合修正。
-
ver.1.6.4
Windows C#,C++2022.05.09GUI版VP Analyzer追加。不具合修正。
Linux2022.05.09不具合修正。
-
ver.1.6.3
Windows C#,C++Linux2020.12.22実行環境のライブラリバージョンを変更(CUDA, cuDNN, TensorRT)。マニュアルにGeForce RTX30シリーズの利用方法を追加。バージョン取得API追加。
-
ver.1.6.2
Windows C#,C++Linux2020.11.25C++向け骨格フレーム取得IFにタイムスタンプ取得IFを追加。キャリブレーション設定リロードAPI追加。不具合修正。
-
ver.1.6.1
Windows C#,C++Linux2020.11.06設定ファイル指定機能追加。その他不具合修正。
-
ver.1.6.0
Windows C#,C++Linux2020.09.09TensorRT7.1 / CUDA11.0 に対応。ネットワークカメラ対応。CSV出力フォーマット追加。その他不具合修正。
-
ver.1.5.3-NX
Jetson Xavier NX2020.06.29マニュアル「6. カメラ配置」の説明を変更。不具合修正。
-
ver.1.5.2
Jetson AGX Xavier2020.6.11CSV出力フォーマット追加。その他不具合修正。
-
ver.1.5.1
Windows C#,C++Linux2020.02.07設定項目を変更、動画解析ツールの名前を「VPAnalyzer」に変更。その他不具合修正。
-
ver.1.5.0
Windows C#,C++Linux2019.07.31C#向けDLL「VisionPoseWrapper.dll」を「VisionPoseCSharp.dll」に統合。その他不具合修正。
-
ver.1.4.0
Windows C#,C++Linux2019.05.27Windows(C++)・Linux(C++)インターフェース追加。マルチスレッド・マルチGPU推論機能追加。カメラインデックス指定機能追加。カメラレスモード機能追加。その他不具合修正。
-
ver.1.3.0
Windows C#2019.02.27解析速度向上。背骨(SpineMid)の位置を調整。骨格表示時のボーン表示の仕様を変更。キャリブレーション作業の簡易化。その他不具合修正。
-
ver.1.2.0
Windows C#2018.12.26シングルカメラモード追加。精度重視・速度重視の設定項目を追加、その他不具合修正。
-
ver.1.1.0
Windows C#2018.11.19動画・静止画解析用プログラム「VP Analyzer」を追加。その他不具合修正。
-
ver.1.0.0
Windows C#2018.11.01初版リリース。※先行企業のみに提供
VisionPose Single3D
-
ver.1.3.3
iOS/iPadOS2025.08.08Unity向けサンプルプログラム「BodyAndColorWithMICHICO」のビルドに必要なUnityバージョンを変更。
-
Ver.1.0.5
Android2025.08.04使用しているライブラリのバージョンを更新。16KBページサイズに対応。サンプルプロジェクトのTargetSDKを36に変更。BodyAndColorWithMICHICOプロジェクトのUnity版を更新。マニュアルを更新。
-
ver.1.5.0
Windows Unity2025.05.14CUDA/TensorRTのバージョンを更新。cuDNNの依存除去。
-
ver.1.3.2
iOS/iPadOS2024.09.09サンプルプログラムの対象OSを16以上に更新。不具合修正。
-
Ver.1.0.4
Android2024.06.24使用ライブラリのバージョン更新。サンプルプロジェクトのTargetSDKを34に変更。BodyAndColor WithMICHICOプロジェクトのUnity版を更新。マニュアルを更新。不具合修正。
-
ver.1.3.1
iOS/iPadOS2024.06.10不具合修正。
-
ver.1.4.0
Windows Unity2023.11.17 USBドングルによるアクティベーション に対応。不具合修正。
-
ver.1.0.3
Android2023.05.19BodyAndColorJavaの不具合を修正
-
ver.1.3.0
Windows Unity2023.04.17CUDA/cuDNN/TensorRTのバージョンを更新
-
ver.1.0.2
Android2023.04.12サンプルプロジェクトのTargetSDKを33に変更。マニュアルを更新。
-
ver.1.0.1
Android2022.12.22不具合修正。
-
ver.1.0.0
Android2022.08.23初版リリース。
-
ver.1.2.1
Windows Unity2022.05.09GUI版VP Analyzer for Single3Dを追加。不具合修正。
-
ver.1.3.0
iOS/iPadOS2021.12.03安定性制御プロパティを追加。Swift向けサンプルプログラム「BodyAndColor」に静止画・動画解析機能を追加
-
ver.1.2.0
iOS/iPadOS2020.07.06最大3次元解析人数を指定可能なAPIを追加。Swift向けサンプルプログラム「BodyAndColor」を追加。Unity向けサンプルプログラム「BodyAndColor with MICHICO」のビルドに必要なUnityバージョンを変更。
Windows Unity2021.09.29AIネットワーク更新。
-
ver.1.1.0
iOS/iPadOS2020.04.23Xcode11.4及びシミュレータ対応。VisionPoseモジュールの名前をEstimatorに変更。不具合対応。
Windows Unity2021.07.28VideoStreamに対応。カメラインデックス指定機能追加。カメラレスモード機能追加。CSV出力フォーマット追加。設定項目変更。TensorRT7.2 / CUDA11.0にバージョンアップ。不具合修正。
-
ver.1.0.2
iOS/iPadOS2020.02.07不具合対応。
Windows Unity2020.02.07設定項目を変更。動画解析ツールの名前を「VPAnalyzerForSingle3D.exe」に変更。不具合修正。
-
ver.1.0.1
iOS/iPadOS2019.11.08Xcode11.2対応。
Windows Unity2019.09.09不具合修正。
-
ver.1.0.0
iOS/iPadOS2019.10.28初版リリース。
Windows Unity2019.10.28初版リリース(※先行企業のみご提供)。
お見積もり・開発のご相談など
ご購入・お見積もり、開発のご相談やご不明な点がありましたら、気軽にお問い合わせください。
教育機関や学校法人様向けのアカデミックライセンスご希望も承っております。
※現在、法人のお客様のみの販売・ご提供となります。ご了承ください。