
みなさまこんにちは。ネクストシステム広報田中です。
さて現在弊社では、AI(DeepLearning)とWEBカメラを使って人間の骨格を検出するシステム『VisionPose(ビジョンポーズ)』を現在法人のお客様向けに販売しています。
※個人のお客様向けには準備が整い次第別途お知らせいたします。
でもみなさま。こんな疑問はありませんか?
骨格検出したはいいけど、精度が悪かった場合どうするの?

この動作の時どうしてもズレるのよね
通常、深度センサーつきカメラの場合は精度が悪かったらそれまでのことが多く、環境を変えたりすることくらいしか対策がありません。
実は弊社では最近
特定動作の教師データを作成するシステム『アノテーションツール』というものを開発しました。
これにより自社での追加学習が可能になったのですが、どうやらこの疑問の答えがここにあるようなのです。
というわけで今回は!銭○警部ばりのしつこさで開発者の方々にヒアリングしてきたので、
Notエンジニアの広報担当目線で、できるだけわかりやすくVisionPoseの追加学習周りのことをまとめてみようと思います。
もくじ
『VisionPose(ビジョンポーズ)』とは?
本題に入る前に、『VisionPose(ビジョンポーズ)』とは、DeepLearningとWEBカメラを使って人間の骨格を検出するシステムです。
2017年10月にKinectが販売中止になるという事件から開発を始めた国産製品となっています。
現在研究目的やスポーツ分野などなど、様々な分野からお問い合わせをいただいています。
最近だとMMD用にモーションキャプチャとして利用したい!というご相談も多いですね。
まずVisionPoseってなんなの?という方はこちらからご確認ください。


追加学習って何?
VisionPoseがどんなものなのかわかったところで、いよいよ今日の本題です。
VisionPoseは骨格を検出するために、
「人間の骨格ってこうなっているんだよー!」
ということを教えてあげる必要があるんですが、人間は色んな体勢を取ることが可能なので、この動きの時の人間の骨格がどこにあるのかというのをミリ単位でいちいち教えるのは大変ですよね。
だから全て教えるのではなく、VisionPoseに基本となるものだけ学習してもらって、あとは自分で考えてもらうのです。
教えるための教材として、色んな体勢の正しい骨格座標が入った写真データ(以下教師データと言います)を使います。
意訳ですが人間の骨格を勉強するための答えつき参考書みたいなものです。

答え合わせして逆算して判断基準(重み)を変えていくんです。
この参考書を渡すと、VisionPoseは一回今までの経験から自分で問題をといて、答え合わせをし、自分の今までの間違いを正します。これを学習と言います。

驚異の吸収能力で若者文化も積極的に取り入れていくスタイル
すると何通りもの画像から、AI(DeepLearning)が人間の骨格の規則を覚えてくれるんです。この教師データを利用して学習させたデータを学習済データ(モデル)と言います。

お前・・・一体何があった・・・
学習させたVisionPoseは今まで勉強した情報(教師データ)を応用して、勉強させた教師データの中にない体勢の人間の骨格も検出してくれるようになるんです。

この後合格してかっこいい彼氏ができ人生バラ色になるパターン。一方ライバルは試験に落ちます。
ただ、この学習済データ(モデル)を使って検出した骨格の精度が悪いともう一回教えてあげないといけません。
このもう一回教えてあげる行為を追加学習と言います。

追加学習ができるようになって何が変わったの?
今までのα版までは追加学習ができなかったので、
一度作った学習済データ(モデル)の骨格の検出精度が悪い場合、別の学習済データ(モデル)に入れ替える必要がありました。
しかしこの度、追加学習が可能になった(※)ため、
VisionPoseで一度骨格を検出して「検出されにくい動作」があった場合、さらに修正を重ねるサイクル(学習→認識→認識精度に課題がある点をアノテーションツールで修正→学習→認識・・・)を回すことによって
無駄なく半永続的にVisionPose(学習済データ)を進化させ続けることが可能になりました。
※追加学習はオプションサービスです。実施には条件があります。

ちょっと何言ってるのかわからないと思うのでもっと簡単にいうと、追加学習ができるようになったことで、
精度を目的に合わせて調整し、さらに磨きをかけることができるようになったよ!
ということです。
もし『この動作の精度をもっとあげたい!』というニーズがある場合は、弊社と一緒に追加学習をして精度を調整していく流れになります。
もちろん最大限サポートいたします!
アノテーションツールとは?
アノテーションツールとは、VisionPoseのオプションツール(予定)で、
特定動作の教師データを作るためのツールです。
先ほど
色んな体勢の正しい骨格座標が入った写真データ(以下教師データと言います)を使います。人間の骨格を勉強するための答えつき参考書みたいなものですね。
っていうお話をしましたが、VisionPoseに追加学習させるためには、この教師データというものが必要です。
教師データは別会社に作成をお願いすることもできるんですが、追加学習させるたびにに別の会社さんに頼んでいると連携が大変ですし、お客様のご要望に柔軟に対応できない可能性があります。
そんな訳で自社で作ってみたのが弊社のアノテーションツールです。
またAI(機械学習)全般にいえるんですが、
学習したら学習した分だけ精度が良くなるという訳ではなく、一線を越えると、頭打ちになってしまってそれ以上は上がらなくなってしまう傾向があるんですよね。
下の図で見ると、縦軸が正解の値との差になっています。
0に近づけば近づくほど精度が高いってことになるので、これ以上下がらなくなったところで学習を終えます。
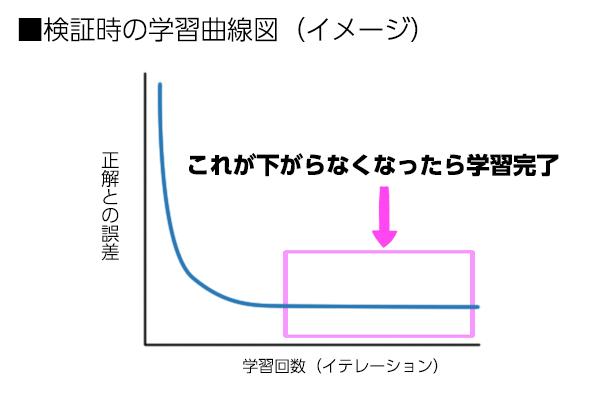
そのため、一番精度がいいところを見極める必要があるんです。
(実はこのチューニング部分が一番センスが問われる部分だったり。)
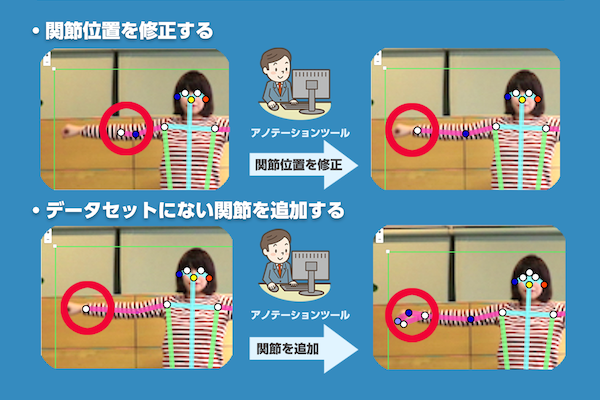
アノテーションツールの主な機能はズバリ関節ポイントの編集です。
使用シーンの例としては下記です。
- 一度VisionPoseを使って骨格を検出してみたけれど、ボーンがうまく取れない場合
- デフォルトのVisionPoseにない関節ポイントを追加したいという場合(要相談)
※現状VisionPoseで検出できる関節ポイントは最大30ポイントです。これ以上増やす場合は要相談となります。
アノテーションツールの操作は?
教師データの作成は弊社が準備したアノテーションツールの環境をお渡しし、お客様の方で作業をしていただくことを想定しています。
操作はとっても簡単!下記のようなマウスでできる簡単な操作を行ってもらいます。
アノテーションツールではまず、画像を読み込み、人が写っている範囲を選択します。
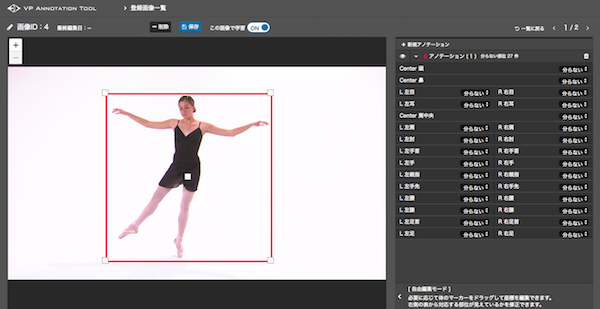
各関節のポイントを画像の人物に合わせて配置していきます。
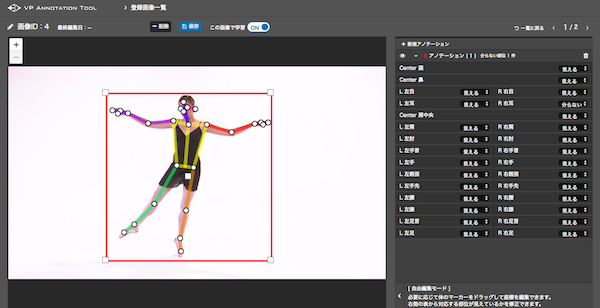
各部位と画像のポイントの位置が反映されています。

こんな感じで正しい関節位置にポイントがあることが確認できたら、保存して教師データが1つ完成です!
これをたくさん行います。
追加学習させたらどうなるの?
アノテーションツールで作成した教師データを利用し、追加学習させた学習済データ(モデル)を使って骨格を検出するテストを行いました。
追加学習する前よりも追加学習させた後の方がうまく検出できていることがわかります。
追加学習途中のVisionPoseを利用しているため、さらに学習を続けることによって、より精度の高い検出が可能です。


まとめ
いかがでしたでしょうか?
VisionPoseで精度が悪かった場合、アノテーションツールを使い教師データを作成し、追加学習をすることで精度を調整し、さらに磨きをかけることができるんですね。
追加学習の大まかな流れとしては下記です。
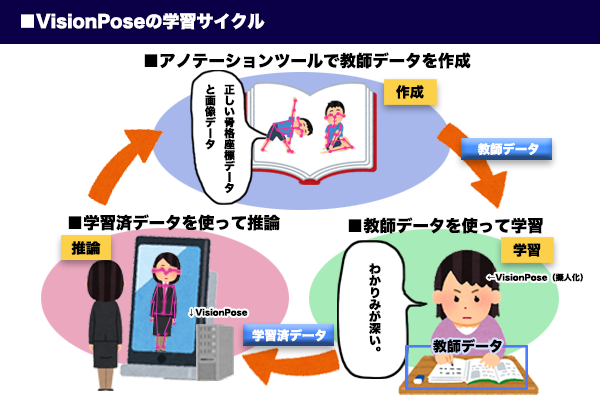
②教師データを使ってVisionPose(学習済データ)に学習させる。
③VisionPose(学習済データ)を使って推論(※)する。骨格が綺麗に検出できているか確認。
④精度が良くなるまで① 0③を繰り返す。
※推論:ここではVisionPoseを使って人間の骨格を検出すること。
VisionPoseは現在2018年3月末に先行企業様を中心にα版をリリースし、そのフィードバック対応を行うことで進化を続けております。
ご期待いただいている皆様には大変お待たせしておりますが、製品版リリースにつきましては年内リリースを目指して開発を進めておりますので、もう少々お待ちいただけましたら幸いです。
また、現在のところお問い合わせが多く、まずは企業様限定とさせていただいておりますが、もっと詳しいお話が聞きたいというご担当者さまは一度お問い合わせくださいませ。
また、リリースの日程など決定しましたら、弊社Twitter・Facebook・WEBサイトでお知らせいたしますので、チェックよろしくお願いいたします。
VisionPoseについてもっと詳しいことが聞きたい場合はこちら!

※現在開発中の商品であるため、今後変更がある場合があります。




